Bei Softwareprojekten besteht oft Bedarf an Kommandozeilenwerkzeugen, die spezifische Aufgaben, wie etwa Code-Generierung, Auswertungen, Paketierung usw., automatisieren. Allzu häufig werden diese Tools ad hoc und unstrukturiert entwickelt, implementiert, rasch fertiggestellt und danach vergessen. Das führt leider dazu, dass sie später schwer zu verstehen und wartungsintensiv sind. Eine gute Software-Dokumentation kann dabei helfen, dieses Problem zu umgehen. Dieser Artikel schlägt eine ergänzende Maßnahme vor: Eine einfache Software-Architektur für Kommandozeilenwerkzeuge, die das Verstehen und die Weiterentwicklung derselbigen erleichtern soll.
Software-Architektur
Automate the boring stuff - Al Sweigart
Das folgende Bild stellt die vorgeschlagene Software-Architektur eines Kommandozeilenwerkzeugs dar.
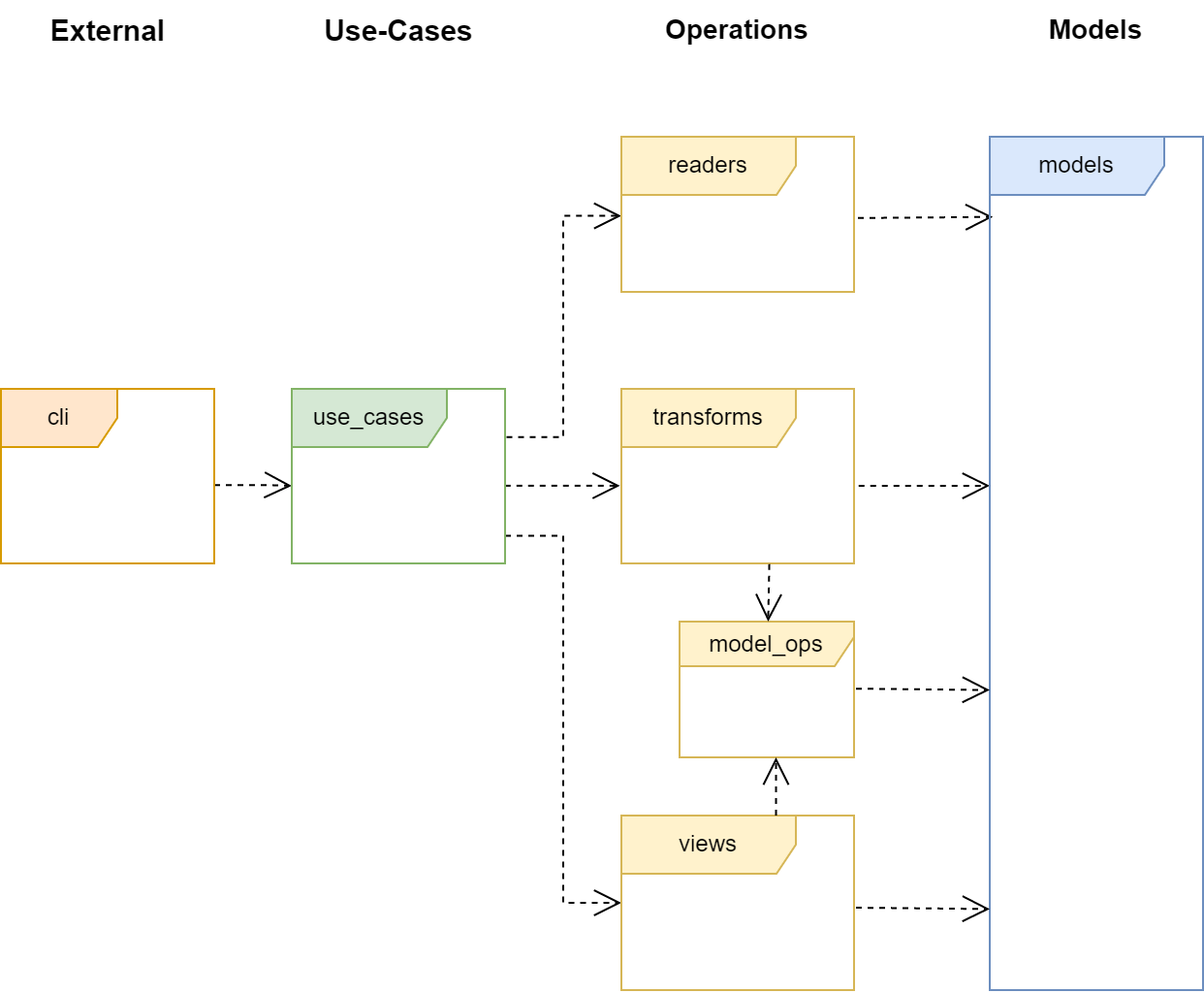
Das Bild zeigt ein UML-Paketdiagramm. Lass Dich jedoch nicht von dieser Bezeichnung irritieren - im vorliegenden Fall werden lediglich Namespaces und ihre Beziehungen zueinander abgebildet. Ein Namespace oder Namensraum ist dabei nichts anderes als ein Container für Code (z. B. Klassen).
Hinweis: In Python definiere ich einen Namespace einfach als Modul inklusive Untermodulen.
Die Pfeile im Diagramm symbolisieren Abhängigkeiten, welche am besten durch den Satz “A benutzt B” erklärt werden. Bezogen auf das Diagramm bedeutet dies zum Beispiel “cli benutzt use_cases”. Beachte dabei, dass die Beziehungen gerichtet sind: Es ist use_cases verboten, cli zu “benutzen”.
Für weiterführende Informationen über die verschiedenen Arten von Abhängigkeiten in UML verweise ich auf meinen eigenen Artikel zu diesem Thema. Diesen findest Du hier!
Die Namespaces im Bild sind in Schichten organisiert. Dies wird zum einen durch die Farbe des Namespaces angedeutet, zum anderen steht jeweils der Name der Schicht über den Namespaces, die sie beinhaltet. Als Beispiel: Die Schicht Operations beinhaltet alle gelb markierten Namespaces.
Schichten
Die Architektur eines Kommandozeilenwerkzeugs teilt sich in vier Schichten auf: External, Use-Cases, Operations und Models. Die wichtigste Regel ist, dass eine Schicht nur Abhängigkeiten zur nächst tieferen Schicht aufweisen darf. Aus schmerzhafter Erfahrung empfehle ich, sich strikt an diese Regel zu halten, um eine ungeordnete und unverständliche Architektur zu vermeiden.
Jede Schicht hat spezifische Aufgaben und Funktionen, die nachfolgend erläutert werden.
External: Diese Schicht verbindet das Programm mit der externen Welt. Hier werden die Kommandozeilenoptionen verarbeitet. Idealerweise sollte hier eine Bibliothek verwendet werden, die diese Aufgabe bewältigt. Hinweis: Bei Python bevorzuge ich Click für diese Aufgabe.
Use-Cases: In dieser Schicht liegen die Anwendungsfälle, hier Use-Case, des Tools. Ein Use-Case beschreibt eine einzige auszuführende Aufgabe, etwa “Konvertiere Datei von Format A nach Format B”. Er sollte entsprechend benannt und dokumentiert werden.
Operations: In dieser Schicht liegen die für die Durchführung der Aufgabe notwendigen Klassen. Im vorliegenden Fall sind die Klassen zum Lesen des Datenmodells (read), Klassen zum Umwandeln eines Datenmodells in eine anderes (transform) und schließlich Klassen zum Anzeigen eines Datenmodells (view).
Models: Schließlich gibt es die Models-Schicht. Diese enthält alle Datenmodelle. Gemäß Wikipedia definieren wir hier ein Datenmodell als ein “Modell der zu verarbeitenden Daten eines Anwendungsbereichs und ihrer Beziehungen zueinander”. Diese Schicht sollte möglichst keine Logik enthalten.
Hinweis: Bei Python empfehle ich den Einsatz von dataclasses und/oder named tuples, um das Datenmodel abzubilden.
Detailierte Erklärung
Die Details unserer Architektur lassen sich am besten anhand eines Beispiels erklären. Wir nehmen an, dass ein Benutzer unser Kommandozeilenwerkzeug folgendermaßen verwendet:
my_tool file1.xyz file2.xyz
Nach diesem Aufruf geschieht Folgendes: Der Code im Namespace cli (external Schicht) wertet die Kommandozeilenargumente aus und führt anschließend einen Use Case aus dem Namespace use_cases aus. Ich sehe den Use Case als eine eigenständige Aufgabe des Kommandozeilenwerkzeugs.
Nehmen wir beispielsweise an, dass my_tool die Aufgabe hat, alle Zeichen in einer Datei in Großbuchstaben zu konvertieren. In diesem Fall könnte der entsprechende Use Case folgendermaßen aussehen:
uc_convert_all_chars_to_uppercase(…)
Hinweis: Bitte beachte, dass alle hier enthaltenen Code-Beispiele keiner wirklichen, existierenden Programmiersprache entsprechen. Sie dienen lediglich dem Zweck eines Beispiels.
Innerhalb des Use Case wird die eigentliche Aufgabe bearbeitet. Da ein Kommandozeilenwerkzeug in der Regel keine weiteren Eingaben während der Ausführung erfordert, kannst Du es immer nach dem EVA-Prinzip strukturieren. Dies bedeutet, dass Du die Aufgabe in einen Eingabe-, einen Verarbeitungs- und einen Ausgabeschritt aufteilst. Der Use Case führt diese Schritte stets in dieser Reihenfolge aus, ohne Ausnahmen!
Achtung: Es ist verführerisch, Dateien während der gesamten Programmlaufzeit zu lesen. Mein Rat: Vermeide das! Du hast ausreichend Speicherplatz. Lade alles, was Du benötigst, in den Speicher und verarbeite es dort. Das macht den Prozess viel klarer.
Das EVA-Prinzip wird in unserer Architektur wie folgt abgebildet:
Eingabe - entspricht dem read Namespace
Verarbeitung - entspricht dem transform Namespace
Ausgabe - entspricht dem view Namespace
Unsere Architektur bietet also jedem dieser Schritte einen eigenen Namespace und damit einen Raum für seine Implementierung. Die Schritte zusammengenommen bilden die Operations Schicht.
Im read Namespace werden Dateien eingelesen und in ein Datenmodell konvertiert, etwa das Lesen von file1.xyz. Das resultierende Datenmodell wird dem Use Case zurückgegeben.
Mit diesem Modell als Argument führt der Use Case eine oder mehrere Operationen im transform Namespace aus, um die Daten in das gewünschte Format zu bringen. Im Beispiel würden wir die im Speicher vorhandenen Zeichenketten in Großbuchstaben umwandeln und sie dann an den Use Case zurückgeben.
Schließlich wird das transformierte Modell durch Operationen im view Namespace zur Anzeige gebracht. Im Beispiel bedeutet das, wir speichern die Ergebnisse in file2.xyz.
Zusammengenommen könnte der Beispiel Use-Case nun wie folgt aussehen:
uc_convert_all_chars_to_uppercase(…) {
// Eingabe
model = read.read_file(...)
// Verarbeitung
t_model = transform.transform_model(model)
// Ausgabe
view.write_tmodel(t_model)
}
Der Namespace model_ops, wie im UML-Diagramm dargestellt, nimmt eine Sonderstellung ein. Er enthält allgemeine Modelllogik, die auch von den Views verwendet werden kann und sollte. Oft handelt es sich dabei um Iteratoren, die ein Modell auf bestimmte Weise darstellen. Es wäre paradox, diese Logik in jedem Namespace separat zu implementieren, deshalb gibt es den model_ops Namespace.
Ein Wort der Warnung: Der Namespace models ist nicht dazu gedacht, Geschäftslogik zu beinhalten, die über den Anwendungsbereich eines Modells hinausgeht. Für diesen Zweck kann der Namespace model_ops ebenfalls genutzt werden. Wo genau die Grenze gezogen wird, hängt von Deiner persönlichen Einschätzung ab.
Warum so konkret? Das ist schlecht testbar!
Wenn du das vorherige Beispiel und die Architektur genauer anschaust, wirst du sehen, dass Funktionen aus einem Namespace direkt von Funktionen in einem anderen Namespace aufgerufen werden. Beispielsweise verwendet ein Anwendungsfall Funktionen aus dem transform Namespace. Selbstverständlich ist es auch möglich, alles als Objekte auszuführen und diese Objekte gegen Interfaces zu implementieren. Diese Interfaces werden anschließend als Kommunikationskanal zwischen den Schichten verwendet. Dieses als Dependency Inversion bekannte Prinzip ist natürlich nicht ausgeschlossen. Insbesondere bei statisch typisierten Programmiersprachen (z.B. C++) würde ich bei komplexen Aufgaben diesen Weg wählen. Es ermöglicht eine testbarere Applikation, macht das Ganze aber meiner Meinung nach weniger übersichtlich. Für einfache Projekte rate ich daher davon ab.
Für dynamisch typisierte Programmiersprachen (z.B. Python) besteht zudem die Möglichkeit, Aufrufe in zu testendem Code zu “patchen”. Ein Beispiel hierfür ist das unter Python bekannte Monkey Patching. Es ermöglicht die Modifikation von Code während der Laufzeit. Dies erlaubt das Einfügen von Mocks, wie beim Dependency Inversion Prinzip, aber ohne den zusätzlichen Schritt, Interfaces einzufügen. Dies stellt häufig eine gute Alternative dar, sollte eine testbares Tool erforderlich sein.
Projektstruktur
Zum Abschluss steht die Frage im Raum, wie sich die Architektur in einem Projekt umsetzen lässt. Momentan verwende ich den Ansatz, für jeden Namespace ein eigenes Verzeichnis zu erstellen. Dabei bevorzuge ich eine flache Abbildung der Architektur auf die Verzeichnisse, sprich, alle Namespaces befinden sich unmittelbar unter dem Hauptverzeichnis.
Das bedeutet allerdings nicht, dass die Schichtenarchitektur missachtet werden sollte. Mit Blick auf diese Aspekte schlage ich folgende Projektstruktur vor:
.\external
.\model_ops
.\models
.\readers
.\transforms
.\use_cases
.\views
{: .notice–info} In Python finden sich unter den Verzeichnissen die Module, in denen die jeweiligen Objekte gespeichert sind.
Für sehr einfache Projekte lässt sich die vorgeschlagene Struktur auch in einer einzigen Datei umsetzen. Es liegt in Deinem Ermessen, die Struktur so zu gestalten, dass sie stets nützlich und praktikabel bleibt.
Zusammenfassung
Der Artikel präsentiert eine einfache, schichtenbasierte Architektur für die Entwicklung von Kommandozeilenwerkzeugen. Die Architektur besteht aus vier Hauptbestandteilen: External, Use-Cases, Operations und Models. Dabei dient die External-Schicht als Brücke zur Außenwelt, die Use-Cases-Schicht definiert die Aufgaben des Tools, die Operations-Schicht stellt Funktionen zur Aufgabendurchführung bereit und die Models-Schicht beherbergt die Datenmodelle. Diese Struktur erleichtert das Verständnis und die Entwicklung solcher Werkzeuge.